
When functional safety calculations are discussed, engineers often focus on things like hardware fault rates, test intervals, or architectural constraints. One input that is often misunderstood — or misused — is MTTR: Mean Time to Restore. While it sounds simple, this term carries specific meaning in the context of IEC 61511-1 and can significantly impact SIL verification and spurious trip rate (STR) evaluations.
This article is a beginner’s guide to what MTTR actually is, when it should (and should not) be used in probability of failure on demand (PFDavg) calculations, and how getting it wrong could lead to overconfident or unrealistic safety claims.
What Is MTTR (Mean Time to Restore)?
Per IEC 61511-1, MTTR refers to the time it takes to restore a safety instrumented function (SIF) to its proper operating state after a failure has occurred. Importantly — and often overlooked — this is different from mean repair time (MRT).
This includes the following four components:
- (a) Time to detect the failure – meaning from the point of failure to when the diagnostic alert is triggered
- (b) Time spent before starting the repair. Such as paperwork and ordering parts.
- (c) Time to do the repair itself.
- (d) Time to perform the restoration
So:
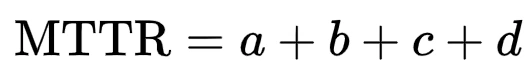
In contrast, MRT (Mean Repair Time) is:
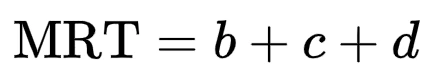
This distinction matters. MTTR as defined in IEC 61511 considers the full window of vulnerability — from initial failure to full recovery. Both MTTR and MRT are used in PFDavg calculations.
This is important because in safety calculations, you’re modeling how long a function is unavailable and how much risk accumulates during that time.
Typical Ranges:
- Low-end (e.g., redundant sensor swap with on-site spares): 2–4 hours
- High-end (e.g., submerged valve with specialist access): weeks or even months
When MTTR Is (and Isn’t) Used in PFDavg
Mean time to restore is NOT always used in PFDavg.
Rule of thumb: It only affects PFDavg when a diagnostic failure is detected and that failure is reported only. Meaning, it doesn’t cause an immediate trip of the SIF, nor does it vote to trip. In essence it means the SIF is still online but functionally unavailable and has effectively already “failed.”
Not used in PFDavg:
The following are examples when PFDavg would not include MTTR components
- Example – A 2oo3 instrument SIF where one instrument has a DD error. That instrument has voted TRUE in the 2oo3 logic. Note this is a common scenario and is a typical way SIFs are designed.
- Example – a 2oo3 instrument where one instrument has a DD error. The system is designed to trip the ENTIRE SIF (this is a rare scenario but could happen)
Incorrect usage example: Applying MTTR to a demand-mode final element that fails silently and has no on-board diagnostics. This underestimates PFDavg.
MTTR Impact on PFDavg
This concept can influence PFDavg calculations in some hard-to-understand ways. The first way is the classic method of DD failure which has the most impact. The second is included as it is very adjacent to MTTR, but is actually another term called mean repair time (MRT).
1. DD Failures that are Reported only
In this case, a component within the SIF experiences a dangerous detected failure (DD) that is reported but not acted upon with a trip nor vote-to-trip. The SIF remains active, but risk is accumulating because the failure has not yet been remedied. It is assumed the SIF is non-operational.
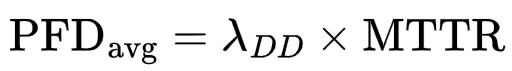
Where:
- λDD = dangerous detected failure rate
- MTTR = mean time to restore
2. Very Closely Related – SIF Bypass Periods (e.g., Proof Testing or Maintenance)
When the entire SIF is placed in bypass — such as during proof testing or temporary overrides — MRT (not MTTR) contributes. The logic is that if a failure is discovered during testing, the SIF must be restored, so MRT becomes relevant.
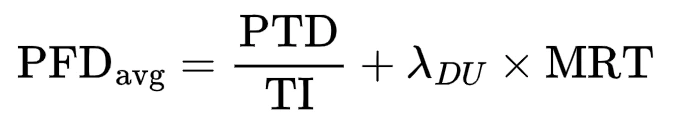
Where:
- PTD = proof test duration
- TI = test interval
- λDU = dangerous undetected failure rate
- MRT = mean repair time
It can be confusing that λDU is included as the failure was “detected” during proof testing. Reminder, the “detected” versus “undetected” applies to diagnostics. If a proof test finds a seized solenoid valve, that would fall under λDU. It can also be confusing that MTTR and MRT can equal each other in times of fast diagnostics.
How Much Does MTTR Contribute to PFDavg?
Now that we’ve seen where Mean Time to Restore enters the PFDavg equations, the next logical question is: how much of the total PFDavg is typically due to this value?
The answer depends on the architecture and diagnostic design of the SIF, but in many cases the MTTR-related terms can be a major portion of the overall PFDavg.
Example Breakdown:
Suppose a SIF has the following contributors:
- Dangerous undetected term (TI/2 component): 6.00E-3
- Diagnostic-only (λDD × MTTR): 2.00E-3
- Bypass and restoration term: 1.00E-3
Total PFDavg = 9.00E-3
In this example, MTTR-based contributions account for 3.00E-3, or 33% of the total PFDavg.
Sensitivity to MTTR Changes
If the time the SIF is unavailable increases from 8 hours to 72 hours or beyond — as can easily happen with inaccessible equipment — that 33% could grow to 50% or more of the total risk profile.
This reinforces a key takeaway:
It isn’t just a footnote — it’s a meaningful design and reliability driver.
When conducting SIL verification, always explore how much of your calculated PFDavg comes from MTTR-related sources. If it’s significant, you may want to revisit response logistics, spares availability, or automated recovery strategies. Designing a SIS is a balance of many things.
Impact on Spurious Trip Rate (STR)
A longer MTTR increases the exposure window for nuisance or spurious trips. Consider a logic solver that falsely detects a dangerous condition. If the system cannot be restored quickly, operations may suffer unnecessary downtime or escalation.
Designs that balance fault tolerance, diagnostic alerts, and realistic restore times can minimize the impact of STR on both safety and availability. Different facilities will have completely different tolerances of STR. Perhaps one per year is acceptable, perhaps not.
What IEC 61511-1 Says
IEC 61511-1 emphasizes the need to use realistic — not idealized — values in SIL verification.
“The MTTR shall take into account all delays including diagnosis, personnel response, spares availability, and repair.” (paraphrased for clarity)
Be cautious of defaulting to 8 hours. Unless supported by site history, vendor specs, or service agreements, this assumption could invalidate a SIL claim.
Common Mistakes
- Confusing MTTR with MRT
- Using overly optimistic values — e.g., assuming parts, tools, and staff are instantly available
- Ignoring logistics — A poorly managed work order system may introduce delays of several days
- Assuming the same value for all elements — A sensor may be quick to restore, but a final element might require complex isolation and drainage
Best Practices for MTTR in SIL Verification
- Document separately for each device type (sensor, logic solver, final element)
- Source your data: field data, OEM specs, or reliability databases (OREDA, etc.)
- Challenge vendor-provided values if they seem unrealistic
- Responsibility: SIS designers typically own the MTTR assumption, but input from operations and maintenance is essential
- Record all assumptions in the Safety Requirements Specification (SRS) and in SIL verification reports
Q&A
1. When does mean time to restore impact PFDavg?
Only when a component of a SIF has detected a failure and reported it only. Thus, the SIF is unavailable but not tripped.
2. How does MTTR differ from MRT?
The former includes detection time (a); MRT starts with diagnosis (b). MTTR is longer and more conservative.
3. Do these values affect high-demand SIFs?
Generally no — high-demand systems use different metrics like PFH (probability of failure per hour).
4. Should MTTR differ by component?
Yes. Sensors, logic solvers, and final elements can have drastically different restore times.
5. Can MTTR be impacted by facility bureaucracy or procurement delays?
Absolutely. Delays in approvals, permits, or spare part procurement can dramatically increase the time a SIF is unavailable. These should be discussed and accounted for in determining these values. It could be that the architecture needs to change if the facility is unwilling to have working spares.
Conclusion
Mean time to restore might seem like a small parameter, but it has outsized influence on how we evaluate and justify risk reduction in a functional safety system. Whether you’re calculating PFDavg or trying to keep STR under control, using accurate, documented, and conservative MTTR values helps ensure your SIL claims are realistic — and defensible.
Audit your assumptions. Align with IEC 61511. And don’t let this “minor” input undermine your entire safety case.
Limble has a great article discussing MTTR and comparing it with other similar concepts.